
- Published on
Extract tokens from a Drupal database dump
- Authors
- Name
- Christophe Jossart
- Mastodon
- @colorfield




While working on migrations from Drupal 7 to 8 it could be necessary to convert tokens from formatted text fields + get an idea of how many of them are in the database for estimation, e.g. to see if it is possible to rely on Token Filter or if there are custom tokens/filters.
It might be possible with the legacy codebase to retrieve some hints with filters, but this is not a guarantee to discover everything, as they could be transformed in several ways (custom or contrib projects / php format stored in the database / ...).
So, the first step is to get an exhaustive list.
Get the regex
Drupal tokens have this pattern:
[token:value or key=value]
Checking the Token::scan method provides the regex work.
So we can start to test our matches with tools like this, on a list of tokens.
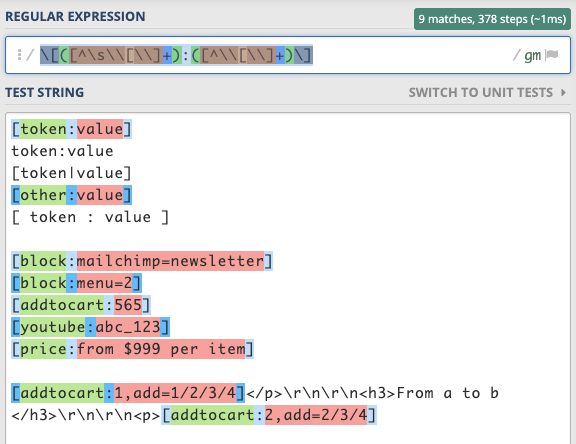
Regex
\[([^\s\\[\\]+):([^\\[\\]+)\]
Test string
[token:value]
token:value
[token|value]
[other:value]
[ token : value ]
[block:mailchimp=newsletter]
[block:menu=2]
[addtocart:565]
[youtube:abc_123]
[price:from $999 per item]
[addtocart:1,add=1/2/3/4]</p>\r\n\r\n<h3>From a to b </h3>\r\n\r\n<p>[addtocart:2,add=2/3/4]
Looks good

Extract the tokens
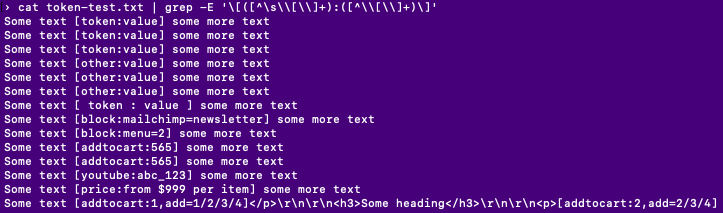
Then let's use grep on the database dump
cat dump.sql | grep -E "\[([^\s\\[\\]+):([^\\[\\]+)\]"
This command will just provide lines with matches, it's already a good start but not really useable.
We also see that [ token : value ] is a match by using grep with this pattern but this is still fine to extract raw results.

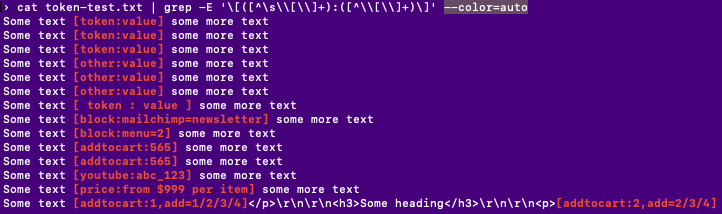
Let's improve this by highlighting the matches, this might be useful to still keep the context, that can be used later on to test if the Drupal 8 filter works properly.
cat dump.sql | grep -E "\[([^\s\\[\\]+):([^\\[\\]+)\]" --color=auto

Better, but we could have only the matches so we can have a plain list without the markup noise that will surround these ones.
cat dump.sql | grep -oE "\[([^\s\\[\\]+):([^\\[\\]+)\]" --color=auto


Then we can reduce the duplicates by piping the result with sort.
cat dump.sql | grep -oE "\[([^\s\\[\\]+):([^\\[\\]+)\]" | sort -u

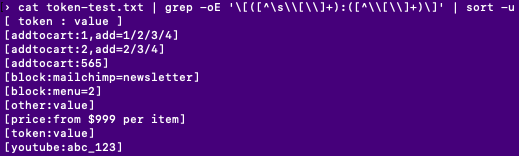
And voilà, based on this list, we can start to write custom Drupal 8 filters or delegate to existing ones.
Depending on the use case, as a final step we could only retain lines that are matching patterns like 'node' or 'filtered_html' so we exclude tokens used by e.g. Webform submissions, ...