
- Published on
Visual regression testing for Drupal migrations with Playwright
- Authors
- Name
- Christophe Jossart
- Mastodon
- @colorfield



When working on a migration that involves to move all content from one editorial solution to another (in the Drupal world, think of CKEditor 4 to 5 with custom plugins, Paragraphs to Layout Builder or Gutenberg, ...) it can be good to have various review methods.
Even if there is close to 100% test coverage based on mock data, it doesn't mean that every single edge case is tested. It can especially be tricky with setups that are combining nested Paragraphs with asymmetrical translations and content moderation, ...
To have an exhaustive way to test, I was wondering how easy it would be to have visual regression testing between a current and a new editorial environment, with a decent sample of content to test.
A while ago, I've been working on this small Sitemap Status contrib project that can be executed on any enviroment to look for potential "content specific" errors. The use case is an automated smoke test, so I was looking for something similar but with visual regression.
It is not meant to be used on a CI system, as content changes quite often, so the idea here is to run it as a sanity check based on 2 snapshots: before and after the migration.
As I wanted something dead simple with enough flexibility, I've excluded no-code solutions that might require too much time to configure and could lead to some limitations or extra work (ngrok when working on localhost, ...).
Among several E2E or visual regression testing solutions out there, like Puppeteer, Nightwatch, TestCafé, Cypress/Percy, ... I had to pick one. Playwright is well adopted/documented, and at a first sight, the visual comparison feature looks lightweight. So I gave this one a try.
It didn't disappoint, in a few lines, I came up with this solution.
Setup
Install Playwright - e.g. with npm npm init playwright@latest
Then create tests/snapshots.spec.ts
import { expect, test } from '@playwright/test'
const baseUrl: string = 'https://www.mysite.org'
const urls: Array<string> = [
'/',
'/en',
'/fr',
'/de',
'/en/another/url',
'/fr/another/url',
'/de/another/url',
]
urls.forEach(async (url) => {
test(`${url} screenshot`, async ({ page }) => {
const pageUrl: string = `${baseUrl}${url}/`
// Replace '/' with '_' then set the starting one as empty.
const screenshotFileName: string =
url === '/' ? 'home.png' : `${url.replace(/\//g, '_').replace(/^_/, '')}.png`
await page.goto(pageUrl)
// Remove the cookie banner. Keep it simple for now,
// no translation or context handling.
await page.getByText('I love cookies').waitFor()
await page.getByText('I love cookies').click()
await expect(page).toHaveScreenshot(screenshotFileName, { fullPage: true })
})
})
Basically, it iterates through a set of urls and takes a page screenshot of each with the {fullPage: true} option. We make sure to get rid of the cookie banner that can hide some content. Each url is stored as a png file. We are using the relative path from the urls array so we can also run this against several environments.
Run it
We need to run it the first time to create the snapshots. We are limiting it to e.g. Chromium here as the goal is to check the migration in the same conditions and not test potential frontend browser issues.
npx playwright test snapshots.spec.ts --project=chromium --update-snapshots
Note the --update-snapshots for the first take.
Then we can run the migration and re-run the snapshots test
npx playwright test snapshots.spec.ts --project=chromium
Finally, we can check the report with
npx playwright show-report
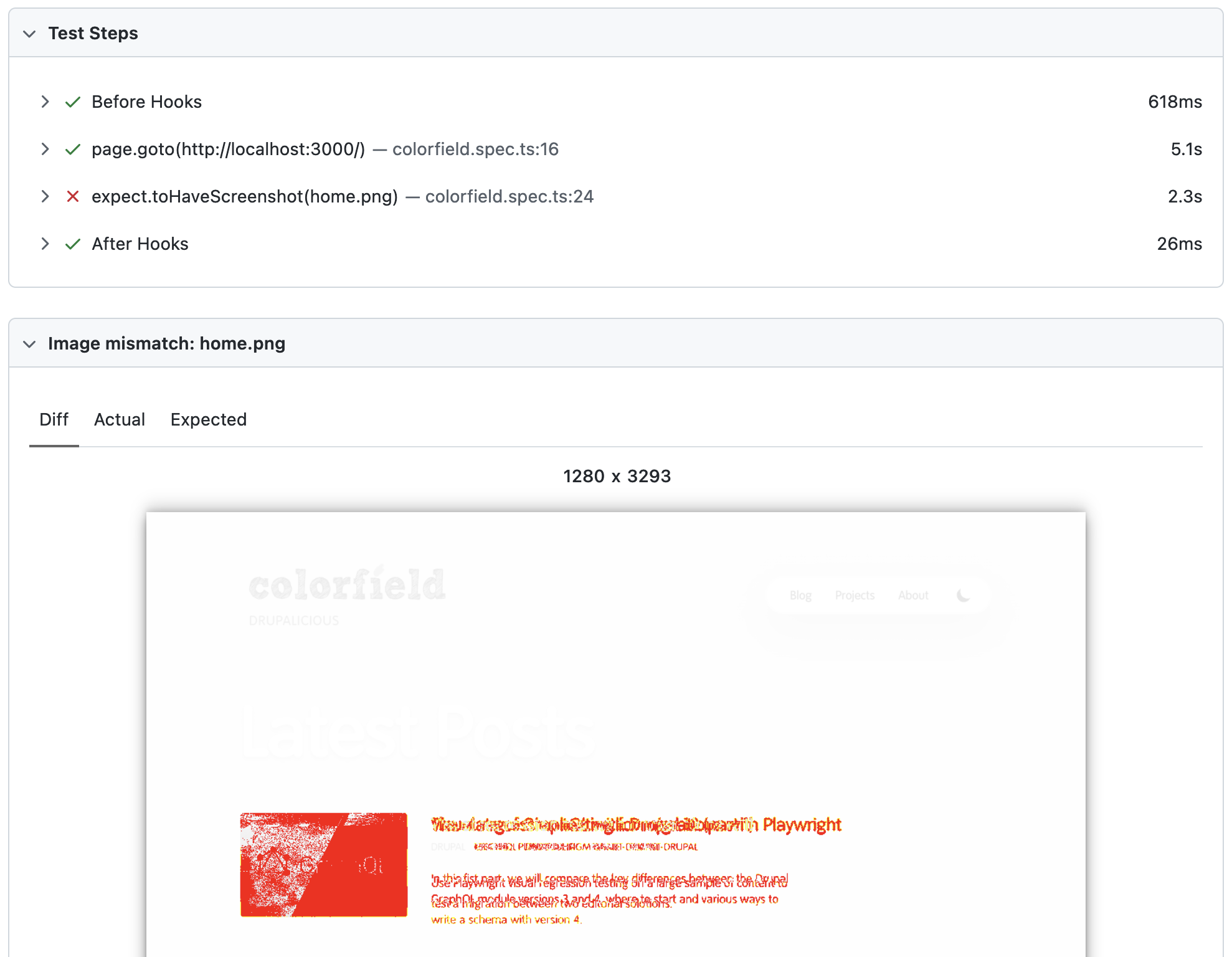
Here is an example diff, when introducing a change.

As a replacement of the static urls array we can read this from the sitemap. A possible solution could also be to reduce the sample to some prio or any other criteria to get a representative set of pages.
We could use a library to load and parse the sitemap, but we want to make sure to have a snapshot of the sitemap as well if we run this locally. Also, as Playwright uses multiple workers by default, let's not produce http calls and xml processing every time. So one way to get quickly a set of urls is to use e.g. wget then sed.
wget https://www.mysite.org/sitemap.xml
sed '/<loc>/!d; s/[[:space:]]*<loc>\(.*\)<\/loc>/\1/' sitemap.xml > urls.txt
Depending on the source of the urls, we can end up with duplicates that will make the test fail. So make sure to remove duplicate urls.
sort file-with-duplicate-urls.txt | uniq -u > urls.txt
Then we can adjust our spec to read from the urls.txt file. As before, we are using the url relative path only so we can run it everywhere (on a local or another environment), so we don't need to match the sitemap locations absolute url and can change the baseUrl.
import { expect, test } from '@playwright/test'
import fs from 'fs'
const baseUrl: string = 'http://localhost:3000'
const urls: Array<string> = []
fs.readFileSync('urls.txt', 'utf-8')
.split(/\r?\n/)
.filter(Boolean)
.forEach(function (line) {
const url = new URL(line)
urls.push(url.pathname)
})
urls.forEach(async (url) => {
test(`${url} screenshot`, async ({ page }) => {
const pageUrl: string = `${baseUrl}${url}`
const screenshotFileName: string =
url === '/' ? 'home.png' : `${url.replace(/\//g, '_').replace(/^_/, '')}.png`
await page.goto(pageUrl)
// Do anything else here, like removing the cookie banner.
await expect(page).toHaveScreenshot(screenshotFileName, { fullPage: true })
})
})
Happy testing!